



















Por Camilo Bravo / @cambraca
Las tendencias en Twitter (“trends”, en inglés), se presentan como “los temas que gozan de popularidad en un momento dado”. El pasado 25 de marzo, aparentemente de la nada, se posicionó en Ecuador la tendencia “#TeVieronLasHuevas”, y de alguna manera se sintió que hubo algo más ahí; que el tema no nació espontáneamente de los usuarios de la plataforma de manera orgánica, sino que tal vez hubo actores que la impulsaron.
La idea de forzar una idea a hacerse viral no es nueva. El marketing ha hecho esto por muchísimo tiempo. Pero esta vez se siente más tramposo al apropiarse de un sistema que es, supuestamente, un indicador de tendencias que surgen de la gente, de lo que está siendo popular en el momento.
Veamos, entonces, si podemos entender mejor este hashtag; si es posible identificar, leyendo los tuits que lo mencionan y entendiendo a los usuarios que los publican, cómo llegó a ser la primera tendencia en el país en menos de un día.
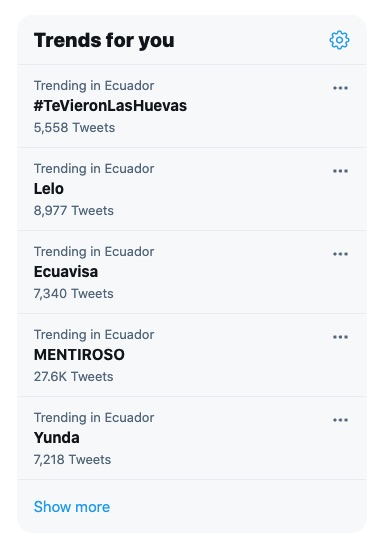
Digamos que queremos descargar la lista completa de tuits con ese hashtag para ver si encontramos algún patrón en los usuarios que lo publicaron inicialmente. Tal vez muchos de estos usuarios fueron creados más o menos al mismo tiempo. Tal vez comparten más características.
Ya que no es factible simplemente leer los miles de tuits involucrados, para el análisis utilizaremos algunas herramientas. Twitter ofrece una interfaz de programación (API, por sus siglas en inglés) que podemos usar para hacer una búsqueda del hashtag, desde un pequeño programa que descargue algunos datos sobre los tuits y sus autores. Para el programa usaremos el lenguaje de programación Go, para el cual existe una librería que hace el uso de la API de Twitter más o menos fácil: github.com/g8rswimmer/go-twitter.
También usaremos la base de datos PostgreSQL para guardar los datos en dos tablas: una de los tuits encontrados, y la otra de usuarios (los autores de los mismos). Se puede pensar en cada tabla como una hoja de Excel, con filas por cada registro y ciertas columnas que definiremos ahora:
- Tabla “tweets”:
- id — identificador de cada tuit, representado por un número
- text — texto del tuit
- author_id — identificador del usuario autor del tuit
- conversation_id — identificador de la conversación, en caso de tener “hilos”
- created_at — fecha y hora de publicación
- query — la búsqueda con la que obtuvimos el tuit (en este caso “#TeVieronLasHuevas”), útil en caso de hacer más búsquedas luego
- Tabla “users”:
- id — identificador del usuario
- username — nombre de usuario de Twitter
- name — nombre real
- created_at — fecha de creación
- followers_count — número de seguidores
- following_count — usuarios a los que sigue
- tweet_count — cantidad de tuits totales publicados por el usuario
En PostgreSQL, creamos las dos tablas con los siguientes comandos:
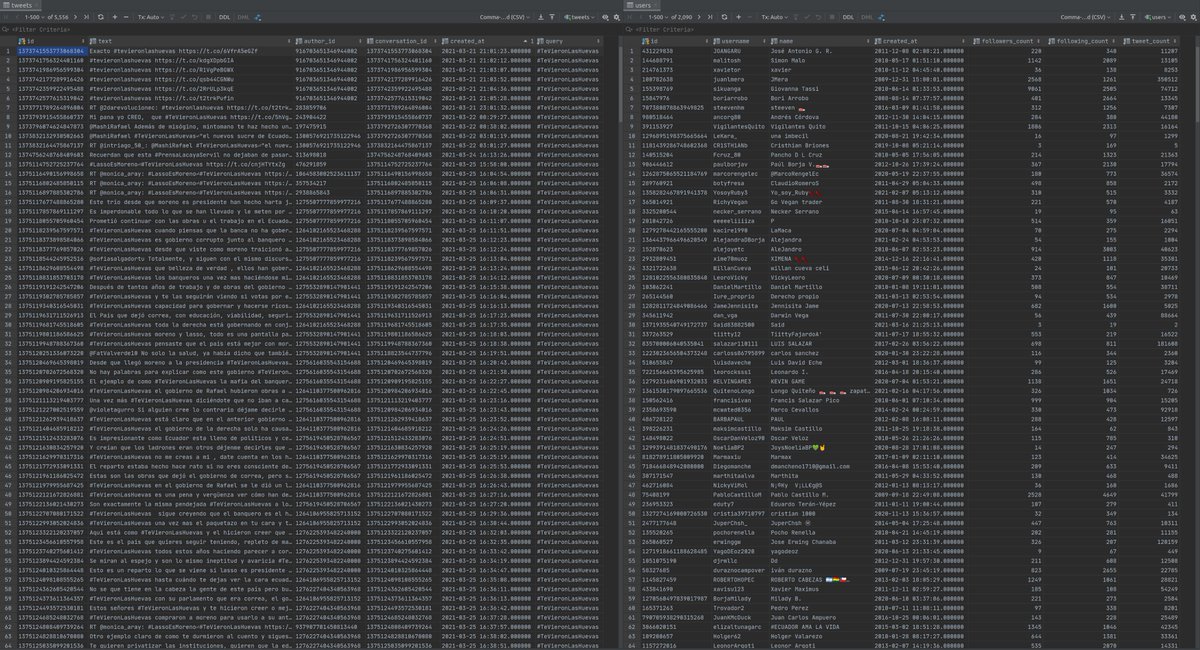
Luego de correr nuestro pequeño programa (link al código más abajo), obtenemos estos datos: alrededor de 5 500 tuits enviados con el dichoso hashtag, por 2 090 usuarios distintos. Todos estos son datos públicos.
Nos interesa ver, de cada usuario, la fecha del primer tuit enviado con el hashtag, además de alguna información sobre cada cuenta de Twitter: número de seguidores, de tuits totales y de días desde el registro de la cuenta. Con el lenguaje de búsquedas de PostgreSQL (“structured query language”, o simplemente “SQL”) se puede proceder así:
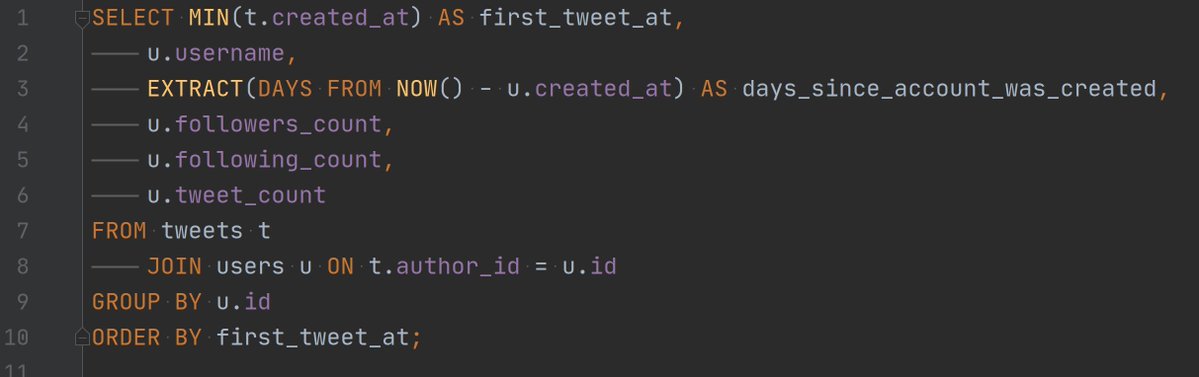
Estos son los primeros resultados. La lista completa tiene 2 090 filas, que corresponden al número de usuarios que encontramos antes:
Poniendo los datos en una hoja de cálculo podemos hacer un gráfico… bastante inservible. Algo rescatable que se ve al lado derecho es que empieza a haber cuentas con muchos tuits totales (línea de color verde), es decir, cuentas reales que empezaron a seguir el juego y a tuitear con el hashtag.
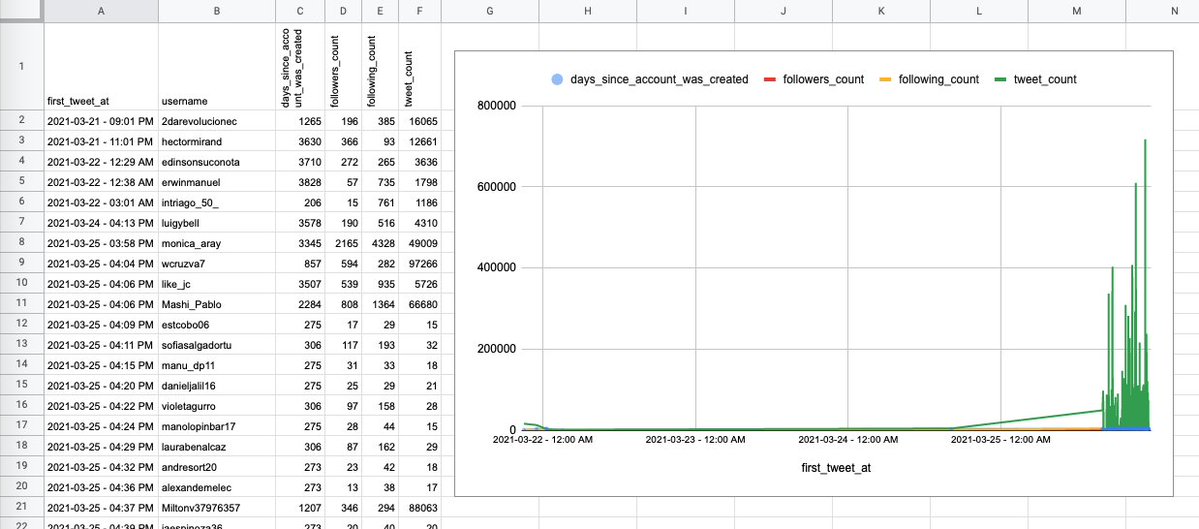
Ahora, filtremos los datos. No nos interesa saber de las cuentas con muchísimos tuits publicados. Quitemos todos los registros cuyas cuentas tengan 100 o más tuits en total. De 2 090, nos quedan 98 filas, es decir, 98 usuarios.
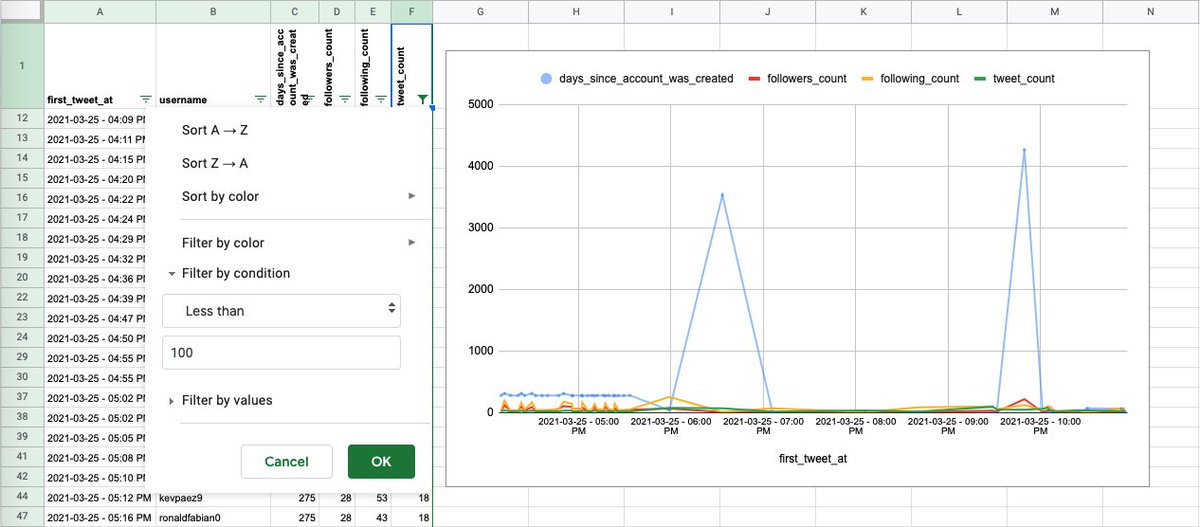
Quitemos también las cuentas que tienen muchísimo tiempo de estar activas. Solo veamos cuentas con menos de 1 000 días de existencia. El gráfico empieza a verse interesante. Tenemos 85 filas.
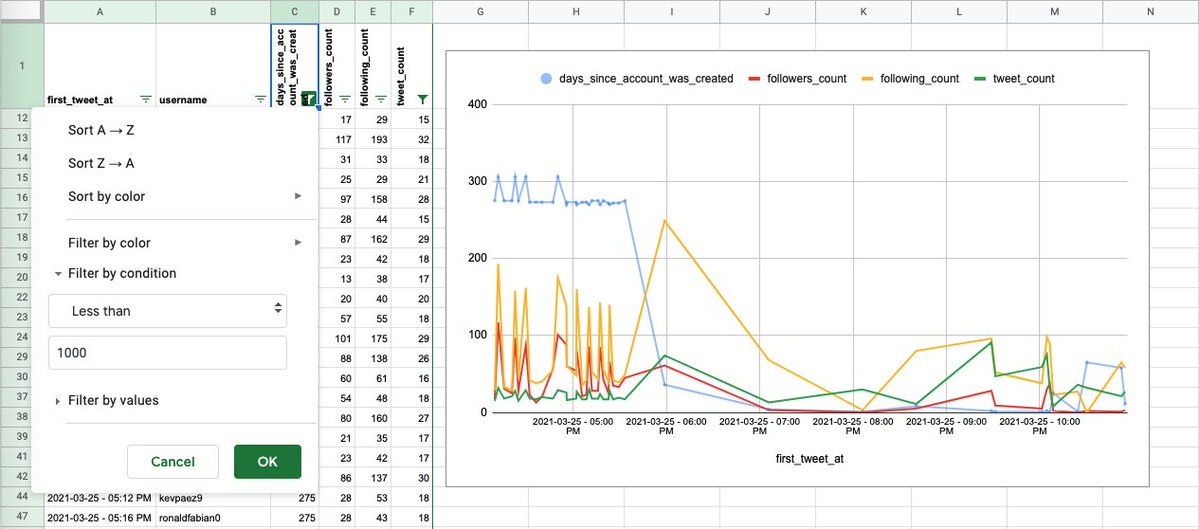
Acerquémonos a lo que nos interesa: los primeros tuits con el hashtag. Filtremos la fecha. 28 filas; 28 cuentas que tuitearon el hashtag el día 25 de marzo. En este punto hay que recordar que mucho de lo que hemos hecho es arbitrario. Pero no deja de ser interesante.
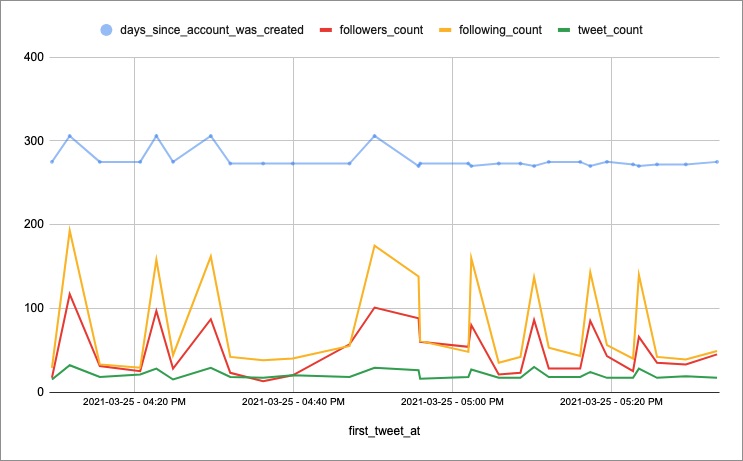
Todas estas cuentas fueron creadas alrededor de junio de 2020 (varias de ellas coinciden en la fecha exacta), siguen a poca gente y tienen relativamente pocos seguidores, y ninguna tiene más de 32 tuits en total. Como dije antes, arbitrario, pero interesante. Es casi como si alguien hubiera impulsado una campaña, así como cuando uno crea un logo y edita videos profesionalmente, y desde sus 28 cuentas falsas se pone a tuitear en el rango de una hora para dar la impresión de viralidad…
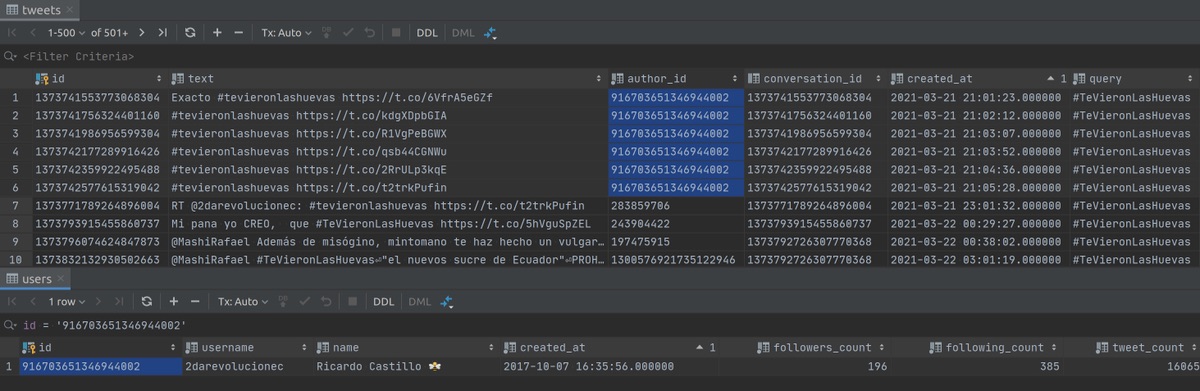
Pero, volvamos a los datos. Estos son los seis primeros tuits, todos de la misma persona, todos con el hashtag y un video. ¡Felicitaciones, Ricardo, hiciste un viral! Con la ayuda de 28 amigos imaginarios, pero lo hiciste.
#NosVieronLasHuevas
Otra cosa divertida que podemos hacer es buscar las cuentas que tengan esta forma en su nombre de usuario, típicamente asociada a bots o usuarios falsos: un nombre y un montón de números.
Hagámoslo, pero ahora usando el hashtag #AndrésPresidente. Corriendo nuevamente el programa, Twitter devolvió 44 938 tuits enviados con ese hashtag por 8 096 usuarios distintos hasta que dijo «no más hasta que pagues mi servicio» (también conocido como “error 429”).
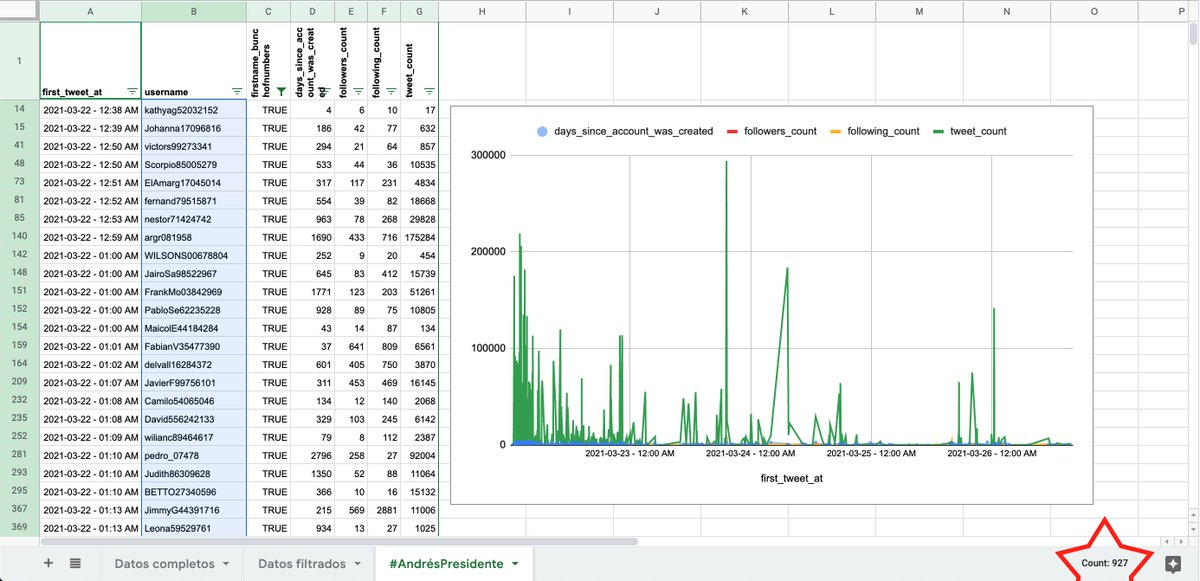
Pongamos los datos en la hoja de cálculo y aumentemos una columna que nos diga si el nombre de usuario calza con esa forma (varias letras y varios números o, para ser más precisos, entre 5 y 20 caracteres alfabéticos, seguido de entre 5 y 20 dígitos). La fórmula en Google Spreadsheets es: `=REGEXMATCH(B2,»\w{5,20}\d{5,20}»)`, donde `B2` apunta a la celda que tiene el nombre de usuario.
De los 8 096 usuarios, 927 coinciden. Es decir, más del 10% son cuentas probablemente falsas, que, desesperadamente, intentan impactar a las tendencias.
En los últimos tiempos, cada vez nos dejamos guiar más por las redes sociales y por sus algoritmos. Algoritmos impenetrables que mantienen despierta nuestra atención, deciden la información a la que tenemos acceso y nos dicen cuáles ideas son las más populares a través de tendencias. Algoritmos que, por su diseño, ya nadie sabe cómo funcionan exactamente. Algoritmos que no son infalibles, que pueden ser engañados. No nos dejemos engañar nosotros también.
Para quienes se mueren de la curiosidad, acá está el código del programa en Go y la hoja de cálculo con todos los resultados.
Artículo basado en un hilo de Twitter que puedes revisar aquí:

¿Ya escuchaste nuestro podcast?








{kind=link}